20148 月26
Java:乱码字符不能插入MySQL的解决办法
.replaceAll(“[^a-zA-Z_\u4e00-\u9fa5]”, “”)
只剩下中文和英文字母了,悲催。
Caused by: java.sql.SQLException: Incorrect string value: ‘\xF0\x9F\x98\xB7’ for column ‘description’
.replaceAll(“[^a-zA-Z_\u4e00-\u9fa5]”, “”)
只剩下中文和英文字母了,悲催。
Caused by: java.sql.SQLException: Incorrect string value: ‘\xF0\x9F\x98\xB7’ for column ‘description’
网易微博登陆验证,第一次请求使用BASE64加密、第二次请求使用MD5+RSA加密,比较变态,于是使用JAVA+JS相结合的方式,调用其JS方法得到加密字符串。
/core1.7.0.js 是经过处理的,删掉几行在JAVA引用中会报错的浏览器对象。
import org.apache.http.HttpResponse;
import org.apache.http.client.CookieStore;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.velocity.util.StringUtils;
import org.nutz.lang.Files;
import org.nutz.lang.util.ClassTools;
import org.nutz.repo.Base64;
import javax.script.Invocable;
import javax.script.ScriptEngine;
import javax.script.ScriptEngineManager;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
/**
* Created by Wizzer on 14-7-7.
*/
public class Netease {
static String index_url = "http://t.163.com/session";
static String login1_url = "http://reg.163.com/services/httpLoginExchgKeyNew";
static String login2_url = "http://reg.163.com/httpLoginVerifyNew.jsp";
static String status_url = "http://t.163.com/share/check/status";
UrlUtil urlUtil = new UrlUtil();
public static void main(String[] args) {
CookieStore cookieStore = new Netease().login("email", "password");
}
public CookieStore login(String userid, String password) {
try {
DefaultHttpClient client = new DefaultHttpClient();
HttpGet get = new HttpGet(login1_url + "?rnd=" + Base64.encodeToString(userid.getBytes(), true) + "&jsonp=setLoginStatus");
get.setHeader("Accept", "*/*");
get.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36");
HttpResponse response = client.execute(get);
int code = response.getStatusLine().getStatusCode();
if (code == 200) {
InputStream in = response.getEntity().getContent();
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
String line = "", res = "";
while (null != (line = reader.readLine())) {
res += line;
}
System.out.println("res:::" + res);
if (res.contains("200")) {
String[] str = StringUtils.split(urlUtil.getStr(res, "setLoginStatus(\"", "\")"), "\\n");
String o = str[1], h = str[2];
ScriptEngineManager sem = new ScriptEngineManager();
ScriptEngine se = sem.getEngineByName("javascript");
se.eval(getJs());
String jiami = "";
if (se instanceof Invocable) {
Invocable invoke = (Invocable) se;
jiami = invoke.invokeFunction("getCode",
password, o, h).toString();
System.out.println("jiami = " + jiami);
}
DefaultHttpClient client2 = new DefaultHttpClient();
client2.setCookieStore(client.getCookieStore());
HttpGet get2 = new HttpGet(login2_url + "?rcode=" + jiami + "&product=t&jsonp=setLoginStatus&savelogin=0&username=" + userid);
get2.setHeader("Accept", "*/*");
get2.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36");
HttpResponse response2 = client2.execute(get2);
int code2 = response2.getStatusLine().getStatusCode();
if (code2 == 200) {
InputStream in2 = response2.getEntity().getContent();
BufferedReader reader2 = new BufferedReader(new InputStreamReader(in2));
String line2 = "", res2 = "";
while (null != (line2 = reader2.readLine())) {
res2 += line2;
}
System.out.println("res2:::" + res2);
if (res.contains("200")) {
return client2.getCookieStore();
}
}
}
}
return null;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
private String getJs() {
String jscontent = Files.read(ClassTools.getClassLoader().getResource("").getPath() + "netease" + "/core1.7.0.js");
jscontent += "function getCode(p,o,h){\n" +
"\t\t\t\tvar l=new RSAKey();\n" +
"\t\t\t\tl.setPublic(h,o);\n" +
"\t\t\t\treturn l.encrypt(getMd5(p));\t\t\t\t\n" +
" }";
return jscontent;
}
}
img { max-width : 800px ; width : expression ( this .width > 800 ? 800 : true ) ; height : auto ; }
HSSFWorkbook wb = new HSSFWorkbook(); OutputStream out = new FileOutputStream(“x.xls”); wb.write(out); out.close(); return new File(“x.xls”);
ByteArrayOutputStream out = new ……..;
wb………
out.close();
ByteArrayInputStream in = new ………..(out.toByte…);
return in;
/e/class/userfun.php
function currentPage($classid,$thisid){
global $class_r;
$fr=explode('|',$class_r[$classid][featherclass]);
$topbclassid=$fr[1]?$fr[1]:$classid;//取得第一级栏目id
if ($topbclassid==$thisid) {
echo "class='cur'";
}
else {
}
}
头部模板:
首先配置好运行环境:
其次修改nginx配置文件:
server {
listen 80;
server_name localhost;
location ~ ^/bbs/.+\.php$ {
alias E:/xuetang/cn/bbs;
rewrite /bbs/(.*\.php?) /$1 break;
fastcgi_index index.php;
fastcgi_pass 127.0.0.1:9000;
fastcgi_param SCRIPT_FILENAME E:/xuetang/cn/bbs$fastcgi_script_name;
include fastcgi_params;
}
location ~ ^/bbs($|/.*) {
alias E:/xuetang/cn/bbs/$1;
index index.php index.html index.htm;
}
location / {
root E:/xuetang/cn/www;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
location ~ \.php$ {
root E:/xuetang/cn/www;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
}
注意虚拟目录配置要在根目录上面。。
/**
* 发送post请求
* @param string $url 请求地址
* @param array $post_data post数据
* @return string
*/
function send_post($url, $post_data) {
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, "POST");
curl_setopt($ch, CURLOPT_POSTFIELDS,$post_data);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,true);
curl_setopt($ch, CURLOPT_HTTPHEADER, array(
'Content-Type: application/json',
'Content-Length: ' . strlen($post_data))
);
return curl_exec($ch);
}
"oXS2NuPCEB836NRMrsXXXXXX", "content" => $send_msg);
$data_string = json_encode($data);
echo send_post('http://XXX.cn/api/wx/push/custom/text?mykey=XXXXXX', $data_string);
?>
1、上传文件的文件池路径问题
upload.js
filePool : { type : “cn.xuetang.common.file.FilePool”, args : [“/temp/”, 2000] }
将路径改到项目的路径下
public class FilePool extends NutFilePool {
public FilePool(String homePath, long size) { super(webinfPath(homePath), size); }
private static final String webinfPath(String str) { return Mvcs.getServletContext().getRealPath(“/WEB-INF”)+str; }
}
2、Nutz大字段缓存的问题
.nutz/tmp/dao
将 org.nutz.dao.jdbc.nutz_jdbc_experts.js 拷贝到项目类路径下,修改相应的配置,文件夹不冲突即可。
编写执行文件 job.sh
#!/bin/sh CLASSPATH=classes:lib/druid-1.0.1.jar:lib/htmlparser-1.6.jar:lib/log4j-1.2.17.jar:lib/mysql-connector-java-5.1.26-bin.jar:lib/nutz-1.b.50.jar:lib/ojdbc14.jar:lib/quartz-2.2.1.jar:lib/quartz-jobs-2.2.1.jar:lib/slf4j-api-1.6.6.jar:lib/slf4j-log4j12-1.6.6.jar:lib/sqljdbc4.jar:lib/commons-pool2-2.2.jar: #export CLASSPATH java -classpath $CLASSPATH cn.xuetang.job.MyJob &
赋予job.sh 执行权限
chmod a+x job.sh
后台执行,并把标准输出重定向,关闭终端仍在执行
nohup bash /home/work/ImageTask/job.sh > success.log 2>error.log &
输出在当前控制台,关闭该终端时,将退出启动的进程
/home/work/ImageTask/job.sh
每两分钟启动一次,关闭终端不影响任务
crontab -e
/2 * /home/work/ImageTask/job.sh > success.log 2>error.log &
常用命令
复制文件夹 cp -ri apache-tomcat-7.0.53 /usr/local/tomcat1 删除文件夹 rm -rf 解压文件 tar -xzvf apache-tomcat-7.0.53.tar.gz
安装C++编码环境 yum install -y gcc-c++ 安装HTTP GZIP yum install -y zlib-devel
后台运行
java -jar aaa.jarr &
kill 脚本
kill -15 ps -ef|grep server.jar|grep -v grep |awk '{print $2}'
/usr/local/nginx/sbin/nginx -t #测试配置 /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx -s stop #停止服务器
/usr/local/tomcat1/bin/startup.sh /usr/local/tomcat2/bin/startup.sh /usr/local/tomcat8080/bin/startup.sh
查看端口 netstat -an | grep 80
系统
# uname -a # 查看内核/操作系统/CPU信息 # head -n 1 /etc/issue # 查看操作系统版本 # cat /proc/cpuinfo # 查看CPU信息 # hostname # 查看计算机名 # lspci -tv # 列出所有PCI设备 # lsusb -tv # 列出所有USB设备 # lsmod # 列出加载的内核模块 # env # 查看环境变量
资源
# free -m # 查看内存使用量和交换区使用量 # df -h # 查看各分区使用情况 # du -sh # 查看指定目录的大小 # grep MemTotal /proc/meminfo # 查看内存总量 # grep MemFree /proc/meminfo # 查看空闲内存量 # uptime # 查看系统运行时间、用户数、负载 # cat /proc/loadavg # 查看系统负载
磁盘和分区
# mount | column -t # 查看挂接的分区状态 # fdisk -l # 查看所有分区 # swapon -s # 查看所有交换分区 # hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备) # dmesg | grep IDE # 查看启动时IDE设备检测状况
网络
# ifconfig # 查看所有网络接口的属性 # iptables -L # 查看防火墙设置 # route -n # 查看路由表 # netstat -lntp # 查看所有监听端口 # netstat -antp # 查看所有已经建立的连接 # netstat -s # 查看网络统计信息
进程
# ps -ef # 查看所有进程 # top # 实时显示进程状态
用户
# w # 查看活动用户 # id # 查看指定用户信息 # last # 查看用户登录日志 # cut -d: -f1 /etc/passwd # 查看系统所有用户 # cut -d: -f1 /etc/group # 查看系统所有组 # crontab -l # 查看当前用户的计划任务
服务
# chkconfig --list # 列出所有系统服务 # chkconfig --list | grep on # 列出所有启动的系统服务
程序
# rpm -qa # 查看所有安装的软件包
入口函数: @At public void downImage(@Param(“tvid”) int tvid, HttpServletResponse resp, HttpServletRequest req) {
}
使用Nutz文件池:
Globals.FILE_POOL= new NutFilePool(“~/tmp/myfiles”, 10);
源码:
int i = 0;
File f = Globals.FILE_POOL.createFile(".zip");
ZipOutputStream out = new ZipOutputStream(new FileOutputStream(f.getAbsolutePath()));
for (Weixin_image image : list) {
i++;
String filename = Strings.sNull(bbinfo.get(image.getUid())) + "_" + Strings.sNull(userinfo.get(image.getUid())) + "_" + i+".jpg";
String picurl = image.getPicurl();
if (!Strings.isBlank(image.getImage_url())) {
picurl = image.getImage_url();
}
URL url = new URL(picurl);
try {
URLConnection conn = url.openConnection();
InputStream inStream = conn.getInputStream();
byte[] buffer = new byte[1204];
out.putNextEntry(new ZipEntry(filename));
while ((byteread = inStream.read(buffer)) != -1) {
bytesum += byteread;
out.write(buffer, 0, byteread);
}
out.closeEntry();
inStream.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
out.close();
resp.setHeader("Content-Length", "" + f.length());
resp.setHeader("Content-Disposition", "attachment; filename=\"" + tvShow.getPlay_name() + ".zip\"");
Streams.writeAndClose(resp.getOutputStream(), Streams.fileIn(f));
功能比较类似于JEECMS,基于Nutz 所以二次开发非常容易,并且UI表现层完全和JEECMS不一样,主要是ajax+弹出窗口的方式。
Q-Q: 1162-4317
Q群:2631-0065 合肥Android/Java开发-GDG
运行效果:
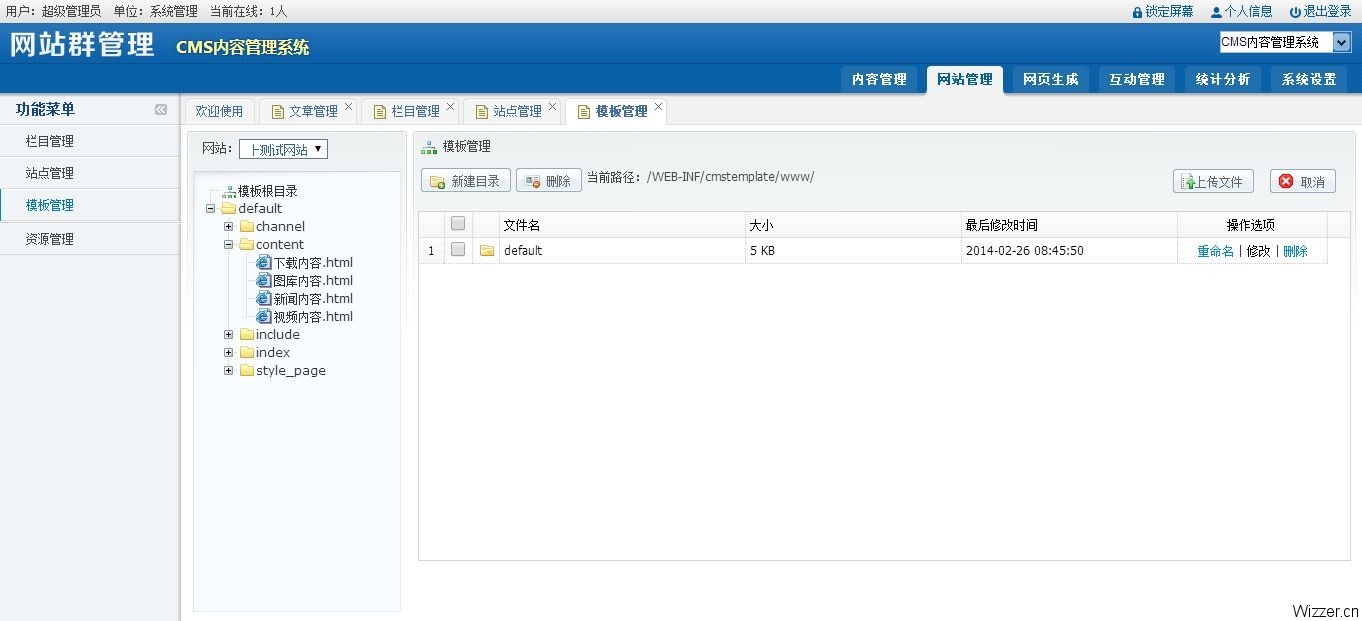
StartSetup 项目启动时新建线程:
package com.hits.core;
import com.hits.modules.cms.task.LoadTask;
import org.nutz.log.Log;
import org.nutz.log.Logs;
import org.nutz.mvc.NutConfig;
import org.nutz.mvc.Setup;
import com.hits.common.config.Globals;
import org.quartz.SchedulerException;
import org.quartz.impl.StdSchedulerFactory;
/**
* 类描述: 创建人:Wizzer 联系方式:www.wizzer.cn 创建时间:2013-11-26 下午2:11:13
*/
public class StartSetup implements Setup {
private final static Log log = Logs.get();
@Override
public void destroy(NutConfig config) {
}
@Override
public void init(NutConfig config) {
try {
//初始化Quartz任务
Globals.SCHEDULER = StdSchedulerFactory.getDefaultScheduler();
new Thread(config.getIoc().get(LoadTask.class)).start();
} catch (SchedulerException e) {
log.error(e);
} catch (Exception e) {
log.error(e);
}
}
}
LoadTask.java 从任务表中加载任务,定时执行类方法:
package com.hits.modules.cms.task;
import com.hits.common.action.BaseAction;
import com.hits.common.config.Globals;
import com.hits.modules.cms.task.bean.Cms_task;
import org.apache.commons.lang.StringUtils;
import org.nutz.dao.Cnd;
import org.nutz.dao.Dao;
import org.nutz.integration.quartz.NutQuartzJobFactory;
import org.nutz.ioc.loader.annotation.Inject;
import org.nutz.ioc.loader.annotation.IocBean;
import org.nutz.log.Log;
import org.nutz.log.Logs;
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
import java.util.*;
/**
* Created by Wizzer on 14-3-4.
*/
@IocBean
public class LoadTask extends BaseAction implements Runnable {
@Inject
protected Dao dao;
private final static Log log = Logs.get();
public void run() {
List tasks = daoCtl.list(dao, Cms_task.class, Cnd.where("is_enable", "=", 0));
Globals.SCHEDULER.setJobFactory(new NutQuartzJobFactory());
for (int i = 0; i < tasks.size(); i++) {
Cms_task task = tasks.get(i);
try {
Map map = new HashMap();
if (task.getTask_type() == 2 || task.getTask_type() == 3) {
map.put("site_id", task.getSite_id());
map.put("channel_id", task.getParam_value());
} else if (task.getTask_type() == 1) {
map.put("site_id", task.getSite_id());
}
JobBuilder jobBuilder = JobBuilder.newJob(getClassByTask(task.getJob_class()));
jobBuilder.setJobData(getJobDataMap(map));
TriggerBuilder triggerBuilder = TriggerBuilder.newTrigger();
if (StringUtils.isNotBlank(task.getTask_code())) {
jobBuilder.withIdentity(task.getTask_code(), Scheduler.DEFAULT_GROUP);
triggerBuilder.withIdentity(task.getTask_code(), Scheduler.DEFAULT_GROUP);
} else {
UUID uuid = UUID.randomUUID();
jobBuilder.withIdentity(uuid.toString(), Scheduler.DEFAULT_GROUP);
triggerBuilder.withIdentity(uuid.toString(), Scheduler.DEFAULT_GROUP);
task.setTask_code(uuid.toString());
daoCtl.update(dao, task);
}
triggerBuilder.withSchedule(getCronScheduleBuilder(getCronExpressionFromDB(task)));
//调度任务
Globals.SCHEDULER.scheduleJob(jobBuilder.build(), triggerBuilder.build());
} catch (SchedulerException e) {
log.error(e);
} catch (ClassNotFoundException e) {
log.error(e);
} catch (Exception e) {
log.error(e);
}
}
if(tasks.size()>0){
Globals.SCHEDULER.start();
}
}
public static CronScheduleBuilder getCronScheduleBuilder(String cronExpression) {
return CronScheduleBuilder.cronSchedule(cronExpression);
}
public String getCronExpressionFromDB(Cms_task task) {
if (task.getExecycle() == 2) {
return task.getCron_expression();
} else {
int execycle = task.getTask_interval_unit();
String excep = "";
if (execycle == 5) {//月
excep = "0 " + task.getMinute() + " " + task.getHour() + " " + task.getDay_of_month() + " * ?";
} else if (execycle == 4) {//周
excep = "0 " + task.getMinute() + " " + task.getHour() + " " + " ? " + " * " + task.getDay_of_week();
} else if (execycle == 3) {//日
excep = "0 " + task.getMinute() + " " + task.getHour() + " " + " * * ?";
} else if (execycle == 2) {//时
excep = "0 0 */" + task.getInterval_hour() + " * * ?";
} else if (execycle == 1) {//分
excep = "0 */" + task.getInterval_minute() + " * * * ?";
}
return excep;
}
}
/**
* @param params 任务参数
* @return
*/
private JobDataMap getJobDataMap(Map params) {
JobDataMap jdm = new JobDataMap();
Set keySet = params.keySet();
Iterator it = keySet.iterator();
while (it.hasNext()) {
String key = it.next();
jdm.put(key, params.get(key));
}
return jdm;
}
/**
* @param taskClassName 任务执行类名
* @return
* @throws ClassNotFoundException
*/
@SuppressWarnings("unchecked")
private Class getClassByTask(String taskClassName) throws ClassNotFoundException {
return Class.forName(taskClassName);
}
}
quartz-2.2.1 配置文件:
# Default Properties file for use by StdSchedulerFactory # to create a Quartz Scheduler Instance, if a different # properties file is not explicitly specified. # # 跳过版本检查 # org.quartz.scheduler.skipUpdateCheck=true org.quartz.scheduler.instanceName = DefaultQuartzScheduler org.quartz.scheduler.rmi.export = false org.quartz.scheduler.rmi.proxy = false org.quartz.scheduler.wrapJobExecutionInUserTransaction = false # 用NutIoc接管Quartz的JobFactory,实现用户需要的注入功能 # org.quartz.scheduler.jobFactory.class=org.nutz.integration.quartz.NutQuartzJobFactory org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool org.quartz.threadPool.threadCount = 10 org.quartz.threadPool.threadPriority = 5 org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true org.quartz.jobStore.misfireThreshold = 60000 # 使用内存JobStore # org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore
NutQuartzJobFactory.java 下载地址:
https://github.com/nutzam/nutzmore/blob/master/src/org/nutz/integration/quartz/NutQuartzJobFactory.java
适用于 Nutz+SWFUpload、Nutz+plupload 、Ueditor 等控件文件上传,验证用户身份。
/**
* 验证用户帐号,保存文件
*
* @param tmpFile
* @param filetype
* @param file_password
* @param file_username
* @param errCtx
* @return
*/
@At
@Ok("raw")
@AdaptBy(type = UploadAdaptor.class, args = "ioc:upload")
public JSONObject uploadOneSave(@Param("Filedata") TempFile tmpFile, @Param("ueditor") String ueditor1, @Param("filetype") String filetype, @Param("title") String title, @Param("file_password") String file_password, @Param("file_username") String file_username, AdaptorErrorContext errCtx) {
boolean ueditor = false;//是否是百度编辑器,编辑器对应的JS要做相应的修改
if ("true".equals(StringUtil.null2String(ueditor1)))
ueditor = true;
System.out.println("ueditor::::::::::"+ueditor);
JSONObject js = new JSONObject();
if (errCtx != null) {
if (errCtx.getAdaptorErr() != null) {
if (ueditor) {
js.put("state", errorMsg(errCtx.getAdaptorErr()));
} else {
js.put("error", errorMsg(errCtx.getAdaptorErr()));
js.put("msg", "");
}
System.out.println("js1::::::::::"+js.toString());
return js;
}
for (Throwable e : errCtx.getErrors()) {
if (e != null) {
if (ueditor) {
js.put("state", errorMsg(e));
} else {
js.put("error", errorMsg(e));
js.put("msg", "");
}
return js;
}
}
}
if ("".equals(StringUtil.null2String(file_username)) || "".equals(StringUtil.null2String(file_password))) {
if (ueditor) {
js.put("state", "错误:请配置文件服务器用户名及密码!");
} else {
js.put("error", "错误:请配置文件服务器用户名及密码!");
js.put("msg", "");
}
return js;
}
Ioc ioc = new NutIoc(new JsonLoader("config/fileserver.json"));
String u = ioc.get(FileServer.class, "fileserver").getUsername();
String p = ioc.get(FileServer.class, "fileserver").getPassword();
if (!u.equals(file_username) || !p.equals(DecodeUtil.Decrypt(file_password))) {
if (ueditor) {
js.put("state", "错误:文件服务器用户名或密码不正确!");
} else {
js.put("error", "错误:文件服务器用户名或密码不正确!");
js.put("msg", "");
}
return js;
}
if (tmpFile == null || tmpFile.getFile().length() < 10) {
if (ueditor) {
js.put("state", "错误:文件大小不可小于10B!");
} else {
js.put("error", "错误:文件大小不可小于10B!");
js.put("msg", "");
}
return js;
}
String filename = tmpFile.getMeta().getFileLocalName();
File file = tmpFile.getFile();
String suffixname = Files.getSuffixName(file).toLowerCase();
String ss = FileType.getSuffixname(upload, filetype);
if (!ss.contains(suffixname)) {
if (ueditor) {
js.put("state", "错误:不允许的文件扩展名,允许:" + ss);
} else {
js.put("error", "错误:不允许的文件扩展名,允许:" + ss);
js.put("msg", "");
}
return js;
}
long len = tmpFile.getFile().length();
filename = filename.substring(0, filename.lastIndexOf(".")) + "." + suffixname;
String date = DateUtil.getToday();
String uuid = UUID.randomUUID().toString().replaceAll("-", "");
String fname = uuid + "." + Files.getSuffixName(file).toLowerCase();
String dest = webPath(date, fname, suffixname);
try {
Files.move(file, new File(dest));
} catch (IOException e) {
e.printStackTrace();
if (ueditor) {
js.put("state", "错误:文件服务器IO异常!");
} else {
js.put("error", "错误:文件服务器IO异常!");
js.put("msg", "");
}
return js;
}
JSONObject fs = new JSONObject();
if (ueditor) {
js.put("state", "SUCCESS");
js.put("original", filename);
js.put("url", "/upload/" + FileType.getFileType(upload, suffixname) + "/" + date + "/" + fname);
js.put("title", title);
} else {
fs.put("filename", filename);
fs.put("filepath", "/upload/" + FileType.getFileType(upload, suffixname) + "/" + date + "/" + fname);
fs.put("filesize", StringUtil.getFileSize(len, 2));
js.put("error", "");
js.put("msg", fs);
}
return js;
}
/**
* 获取上传路径,根据文件类型+日期生成路径
*
* @param date
* @param fname
* @param suffixname
* @return
*/
public String webPath(String date, String fname, String suffixname) {
String newfilepath = Mvcs.getServletContext().getRealPath(
"/upload/" + FileType.getFileType(upload, suffixname) + "/" + date
+ "/");
Files.createDirIfNoExists(newfilepath);
return newfilepath + "\\" + fname;
}
/**
* 根据异常提示错误信息
*
* @param t
* @return
*/
private String errorMsg(Throwable t) {
if (t == null || t.getClass() == null) {
return "错误:未知system错误!";
} else {
String className = t.getClass().getSimpleName();
if (className.equals("UploadUnsupportedFileNameException")) {
String name = upload.getContext().getNameFilter();
return "错误:无效的文件扩展名,支持的扩展名:" + name.substring(name.indexOf("(") + 1, name.lastIndexOf(")")).replace("|", ",");
} else if (className.equals("UploadUnsupportedFileTypeException")) {
return "错误:不支持的文件类型!";
} else if (className.equals("UploadOutOfSizeException")) {
return "错误:文件超出" + StringUtil.getFileSize(upload.getContext().getMaxFileSize(), 2) + "MB";
} else if (className.equals("UploadStopException")) {
return "错误:上传中断!";
} else {
return "错误:未知错误!";
}
}
}
项目部署根目录增加:crossdomain.xml 文件,解决上传控件跨域上传的问题(应用和文件服务器分开部署):
SWFUpload.prototype.setPostParams = function (paramsObject) { this.settings.post_params = paramsObject; this.callFlash(“SetPostParams”, [paramsObject]); };
swfu.setPostParams({ path:$(“#path”).val() });
upload.json 配置文件,增加扩展配置项extOption,内容可以由用户自定义,返回一个Map对象。
我要实现功能是,用户在相册里只允许上传图片文件、视频里只允许上传视频格式的文件等,
结合上传控件和JS,实现在页面级和代码级的文件类型分类限制、分类保存等功能。
Nutz issue 提交需求不被接纳所以只好自己实现了,大家如需要的话可以提issue,希望以后Nutz能内置:
https://github.com/nutzam/nutz/issues/568
upload.json:
var ioc = {
upload : {
type : "org.nutz.mvc.upload.UploadAdaptor",
args : [{refer : "uploadCtx"}]
},
uploadCtx : {
type : "org.nutz.mvc.upload.UploadingContext",
args : [{refer: "filePool"}],
fields : {
ignoreNull : true,
maxFileSize : 10485760,
nameFilter : ".+(jpg|gif|png|jpeg|doc|docx|xls|xlsx|ppt|pptx|wps|pdf|txt|chm|mp3|mp4|3gp|rm|swf|flv|asf|wmv|wma|z|zip|rar|ios|jar)",
extOption: {
"images":"jpg,gif,png,jpeg",
"document":"doc,docx,xls,xlsx,ppt,pptx,wps,pdf,txt,chm",
"music":"mp3",
"video":"mp4,3gp,rm,swf,flv,asf,wmv,wma",
"archive":"z,zip,rar,ios,jar"
}
}
},
filePool : {
type : "com.hits.common.file.FilePool",
args : ["/temp/", 2000]
}
};
改写Nutz源码:
org.nutz.mvc.upload.UploadingContext 类,增加代码:
/**
* 一个扩展配置项,用户可自定义内容
*/
private Map extOption;
public Map getExtOption() {
return extOption;
}
public UploadingContext setExtOption(String extOption) {
this.extOption = Json.fromJsonAsMap(String.class,extOption);
return this;
}
增加一个调用类:
FileType.java
/**
* 类描述:
* 创建人:Wizzer
* 联系方式:www.wizzer.cn
* 创建时间:2013-12-25 下午1:13:30
* @version
*/
public class FileType {
/**
* 根据文件名获取文件类型,默认返回other
* @param upload
* @param suffixname
* @return
*/
public static String getFileType(UploadAdaptor upload,String suffixname) {
Map hm=upload.getContext().getExtOption();
String str = StringUtil.null2String(suffixname).toLowerCase();
Set<Map.Entry> set = hm.entrySet();
for (Iterator<Map.Entry> it = set.iterator(); it.hasNext();) {
Map.Entry entry = (Map.Entry) it.next();
if(entry.getValue().toLowerCase().indexOf(str)>-1)
return entry.getKey();
}
return "other";
}
/**
* 根据文件类型获取文件后缀名,默认返回nameFilter配置
* @param upload
* @param filetype
* @return
*/
public static String getSuffixname(UploadAdaptor upload,String filetype) {
Map hm=upload.getContext().getExtOption();
String str = StringUtil.null2String(filetype).toLowerCase();
if(!"".equals(str)){
Set<Map.Entry> set = hm.entrySet();
for (Iterator<Map.Entry> it = set.iterator(); it.hasNext();) {
Map.Entry entry = (Map.Entry) it.next();
if(entry.getKey().toLowerCase().equals(str))
return entry.getValue();
}
}
String name=upload.getContext().getNameFilter();
return name.substring(name.indexOf("(")+1,name.lastIndexOf(")")).replace("|", ",");
}
}
使用示例:
@Inject
protected UploadAdaptor upload;
@At
@Ok("->:/private/file/uploadOne.html")
public void uploadOne(@Param("filetype") String filetype,HttpServletRequest req){
req.setAttribute("filetype", filetype);
req.setAttribute("allowExtensions", FileType.getSuffixname(upload, filetype));
}
如上所述,在限制文件上传类型的同时,还可以将文件分类保存在不同类型的目录下。
由于Nutz是零配置的,所以通过URL找到处理类以及跳转的页面,就显得很麻烦,不方便维护。
于是,我在大神兽的指导下,实现如下功能:在项目启动时,将URL路径、类、方法、以及跳转页面写入项目中的一个文件中,方便查看。
@UrlMappingBy(value=UrlMappingSet.class)
public class MainModule {
}
在Nutz入口类,加入 @UrlMappingBy。
UrlMappingSet.java 实现在 /WEB-INF/ 目录下生成 paths.txt 文件,记录路径,文件格式如下:
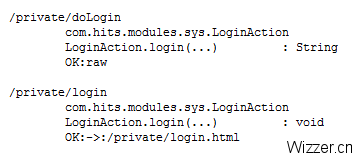
UrlMappingSet.java 源码:
package com.hits.core;
import java.io.File;
import java.lang.reflect.Method;
import org.nutz.lang.Files;
import org.nutz.lang.Lang;
import org.nutz.mvc.ActionChainMaker;
import org.nutz.mvc.ActionInfo;
import org.nutz.mvc.Mvcs;
import org.nutz.mvc.NutConfig;
import org.nutz.mvc.impl.UrlMappingImpl;
/**
* 类描述: 创建人:Wizzer 联系方式:www.wizzer.cn 创建时间:2013-12-19 下午10:36:17
*
* @version
*/
public class UrlMappingSet extends UrlMappingImpl {
private static int count = 0;
public void add(ActionChainMaker maker, ActionInfo ai, NutConfig config) {
super.add(maker, ai, config);
printActionMappingThis(ai);
}
protected void printActionMappingThis(ActionInfo ai) {
String[] paths = ai.getPaths();
StringBuilder sb = new StringBuilder();
if (null != paths && paths.length > 0) {
sb.append(paths[0]);
for (int i = 1; i < paths.length; i++)
sb.append(",").append(paths[i]);
} else {
throw Lang.impossible();
}
sb.append("\n");
// 打印方法名
Method method = ai.getMethod();
String str;
if (null != method)
str = String.format("%-30s : %-10s", Lang.simpleMetodDesc(method),
method.getReturnType().getSimpleName());
else
throw Lang.impossible();
sb.append("\t" + ai.getModuleType().getName());
sb.append("\n\r");
sb.append("\t" + str);
sb.append("\n");
String filepath = Mvcs.getServletContext().getRealPath("/WEB-INF/")
+ "/paths.txt";
File f = new File(filepath);
if (count == 0) {
Files.write(f, sb.toString());
} else {
Files.appendWrite(f, sb.toString());
}
count++;
}
}
使用示例:
/**
你可以自定义取数据区间的值,如下:
offset=0,count=5 取0到5的记录
offset=5,count=10 取5到15的记录
page=3, offset=15,count=20 取15到35的记录
**/
int offset=0;
int count=5;
ExplicitPager pager=new ExplicitPager(offset,count);
QueryResult file=daoCtl.listPage(dao, Oa_doc_file.class, cri,pager);
ExplicitPager 类源码:
package com.hits.common.page;
import org.nutz.dao.pager.Pager;
/**
* 类描述:
* 创建人:Wizzer
* 联系方式:www.wizzer.cn
* 创建时间:2013-12-12 下午3:16:21
* @version
*/
public class ExplicitPager extends Pager {
private static final long serialVersionUID = 1L;
int offset;
int count;
public ExplicitPager(int offset, int count) {
super();
this.offset = offset;
this.count = count;
}
public void setOffset( int offset) {
this.offset = offset;
}
public void setSelectCount( int count) {
this.count = count;
}
@Override
public int getPageSize() {
return count;
}
@Override
public int getOffset() {
return offset;
}
}
分页源代码(可参考上一篇文章,实现自定义SQL多表分页区间取值):
/**
* 根据查询条件分页,返回封装好的QueryResult对象
*
* @param dao
* @param obj
* @param cnd
* @param pager
* @return
*/
public QueryResult listPage(Dao dao, Class obj, Condition cnd,Pager pager) {
List list = dao.query(obj, cnd, pager);
pager.setRecordCount(dao.count(obj, cnd));// 记录数需手动设置
return new QueryResult(list, pager);
}
/**
* 根据自定义SQL分页,返回封装好的QueryResult对象
* @param dao
* @param sql
* @param pager
* @return
*/
public
QueryResult listPageSql(Dao dao, Sql sql, Pager pager) {
if(pager==null)
return null;
pager.setRecordCount(Daos.queryCount(dao, sql.getSourceSql()));// 记录数需手动设置
sql.setPager(pager);
sql.setCallback(Sqls.callback.records());
dao.execute(sql);
return new QueryResult(sql.getList(Map.class), pager);
}
easyui.datagrid 调用示例:
@At
@Ok("raw")
public String test(@Param("page") int curPage, @Param("rows") int pageSize){
Sql sql=Sqls.create("select a.name,b.loginname From sys_unit a,sys_user b where a.id=b.unitid");
return daoCtl.listPageJsonSql(dao, sql, curPage, pageSize);
}
源代码:
/**
* 根据自定义SQL分页,返回封装好的QueryResult对象
* @param dao
* @param sql
* @param curPage
* @param pageSize
* @return
*/
public QueryResult listPageSql(Dao dao, Sql sql, int curPage,int pageSize) {
Pager pager = dao.createPager(curPage, pageSize);
pager.setRecordCount(Daos.queryCount(dao, sql.getSourceSql()));// 记录数需手动设置
sql.setPager(pager);
sql.setCallback(Sqls.callback.records());
dao.execute(sql);
return new QueryResult(sql.getList(Map.class), pager);
}
/**
* 根据自定义SQL分页,返回封装好的 Easyui.datagrid JSON
* @param dao
* @param sql
* @param curPage
* @param pageSize
* @return
*/
public String listPageJsonSql(Dao dao, Sql sql, int curPage, int pageSize) {
Pager pager = dao.createPager(curPage, pageSize);
pager.setRecordCount(Daos.queryCount(dao, sql.toString()));// 记录数需手动设置
sql.setPager(pager);
sql.setCallback(Sqls.callback.records());
dao.execute(sql);
Map jsonobj = new HashMap();
jsonobj.put("total", pager.getRecordCount());
jsonobj.put("rows", sql.getList(Map.class));
return Json.toJson(jsonobj);
}